GenLCA
3D Diffusion for Full-Body Avatars
from In-the-Wild Videos
If you are interested in academic comparisons, please contact Junxuan Li.

Insights
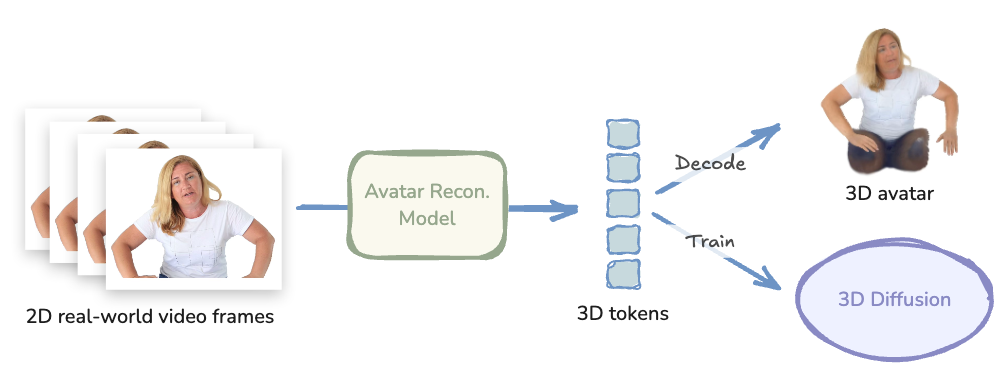
Specifically, we scale up the dataset by repurposing a pretrained feed-forward avatar reconstruction model as an animatable 3D tokenizer. The reconstruction model encodes unstructured video frames of a person into 3D tokens, which can then be decoded into an animatable 3D Gaussian avatar. We then train a flow-based diffusion model, GenLCA.
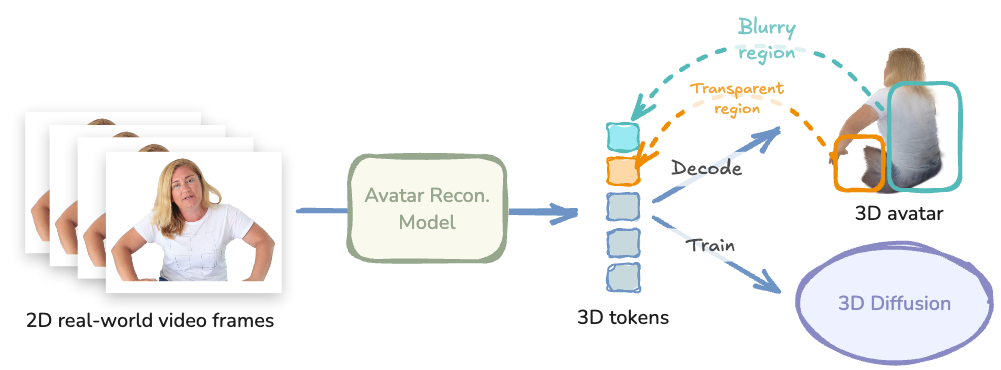
 However, most real-world videos only provide partial observations of body parts, while the reconstruction
model is inherently limited in hallucinating unobserved regions. As a result, excessive blurring or
transparent artifacts often occur in the occluded areas.
However, most real-world videos only provide partial observations of body parts, while the reconstruction
model is inherently limited in hallucinating unobserved regions. As a result, excessive blurring or
transparent artifacts often occur in the occluded areas.
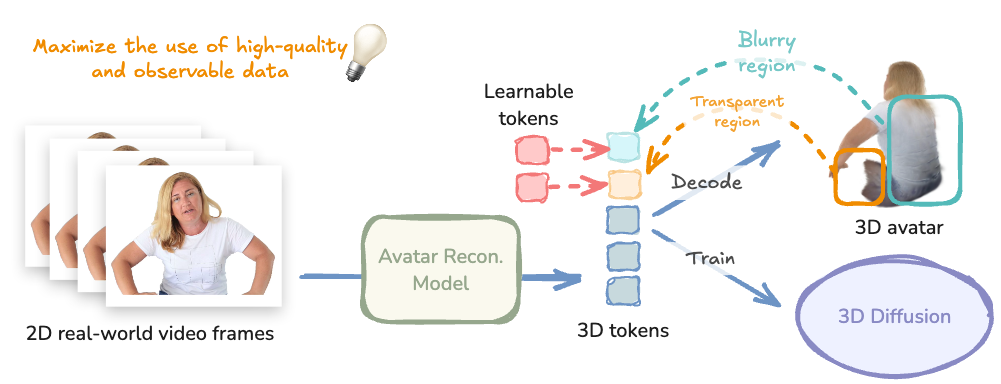
 To address this, we propose a novel visibility-aware diffusion training strategy that replaces invalid
regions with learnable tokens and computes losses only over valid regions. Our approach effectively
enables the use of large-scale real-world video data to train a diffusion model natively in 3D.
To address this, we propose a novel visibility-aware diffusion training strategy that replaces invalid
regions with learnable tokens and computes losses only over valid regions. Our approach effectively
enables the use of large-scale real-world video data to train a diffusion model natively in 3D.
Text-based Generation
GenLCA generates high-quality, animatable 3D avatars from text descriptions. Click on any avatar to explore it in the interactive 3D viewer.
Note: Due to the constraints of the web viewer, we only show static GS results. However, all avatars are fully animatable. Please refer to the videos in Animation Examples.
Animation Examples
Body-part-based Generation
GenLCA generates high-quality, animatable 3D avatars from reference body part images, including face, hair, upper clothes, lower clothes, and shoes. Click on any avatar to explore it in the interactive 3D viewer.
Note: Due to the constraints of the web viewer, we only show static GS results. However, all avatars are fully animatable. Please refer to the videos in Animation Examples.
Animation Examples
Multi-modal Editing
GenLCA supports multi-modal editing operations by leveraging text, RGB images, or scribbles as control signals. Click on any avatar to view it in the 3D viewer.
BibTeX
@misc{wu2026genlca3ddiffusionfullbody,
title={GenLCA: 3D Diffusion for Full-Body Avatars from In-the-Wild Videos},
author={Yiqian Wu and Rawal Khirodkar and Egor Zakharov
and Timur Bagautdinov and Lei Xiao and Zhaoen Su and
Shunsuke Saito and Xiaogang Jin and Junxuan Li},
year={2026},
eprint={2604.07273},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2604.07273}
}
3D Avatar Viewer
Loading description...
Drag to rotate
Right-click to pan
Scroll to zoom