
Existing neural rendering-based text-to-3D-portrait generation methods typically make use of human geometry prior and diffusion models to obtain guidance. However, relying solely on geometry information introduces issues such as the Janus problem, over-saturation, and over-smoothing.
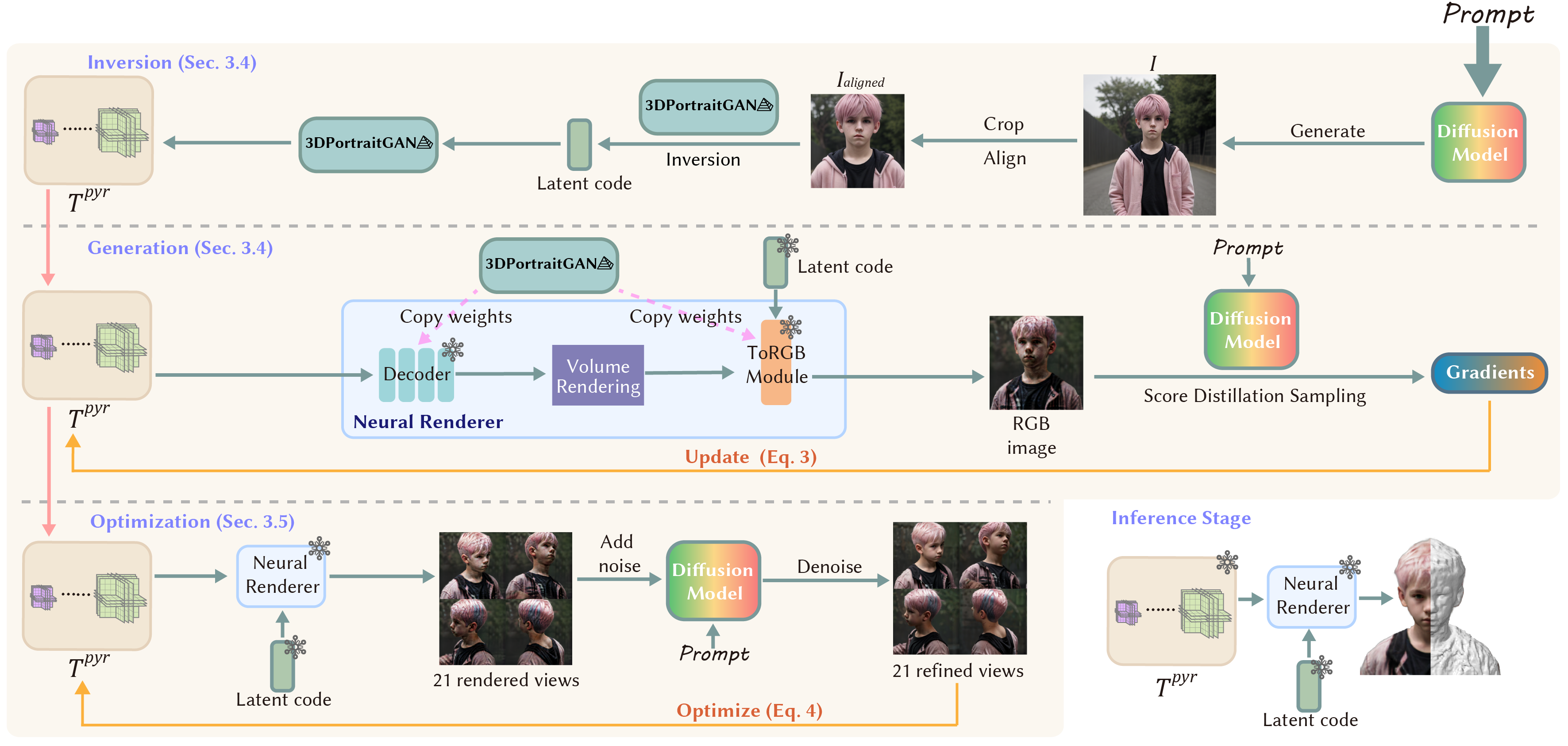
We present Portrait3D, a novel neural rendering-based framework with a novel joint geometry-appearance prior to achieve text-to-3D-portrait generation that overcomes the aforementioned issues. To accomplish this, we train a 3D portrait generator, 3DPortraitGAN-Pyramid, as a robust prior. This generator is capable of producing 360° canonical 3D portraits, serving as a starting point for the subsequent diffusion-based generation process. To mitigate the "grid-like" artifact caused by the high-frequency information in the feature-map-based 3D representation commonly used by most 3D-aware GANs, we integrate a novel pyramid tri-grid 3D representation into 3DPortraitGAN-Pyramid. To generate 3D portraits from text, we first project a randomly generated image aligned with the given prompt into the pre-trained 3DPortraitGAN-Pyramid's latent space. The resulting latent code is then used to synthesize a pyramid tri-grid. Beginning with the obtained pyramid tri-grid, we use score distillation sampling to distill the diffusion model's knowledge into the pyramid tri-grid. Following that, we utilize the diffusion model to refine the rendered images of the 3D portrait and then use these refined images as training data to further optimize the pyramid tri-grid, effectively eliminating issues with unrealistic color and unnatural artifacts.
Our experimental results show that Portrait3D can produce realistic, high-quality, and canonical 3D portraits that align with the prompt.
The pipeline of Portrait3D. During the process of text-to-3D-portraits generation, given a text prompt, we first randomly generate a portrait image by feeding the text prompt into the diffusion model, and then project the generated image into the latent space of our generator. The resulting latent code is used to synthesize the corresponding pyramid tri-grid, which serves as the starting point of the subsequent diffusion-based generation process. Following that, we distill the knowledge of the diffusion model into the pyramid tri-grid through score distillation sampling. This process produces a 3D portrait that aligns with the input prompt. To further enhance the quality of the obtained 3D portrait, we apply the diffusion model to process its rendered images. The refined rendered images are then used as training data to optimize the pyramid tri-grid, yielding the final results.
Qualitative comparison to SOTA text-to-3D approaches: DreamFusion, LucidDreamer, TADA, AvatarCraft, AvatarStudio, HumanGaussian, AvatarVerse, HumanNorm, SEEAvatar, TECA, and our method. The input prompt is presented at the top.

Qualitative comparison to SOTA diffusion-based reconstruction approaches: One-2-3-45, DreamGaussian, Wonder3D, SyncDreamer and TeCH, and our method. The reference prompt is presented at the top, and the reference image (which is also the generated image used for image inversion in our framework) is presented at the left.

We offer a gallery of 300 3D portraits (with their corresponding prompts) generated by our method, all viewable and accessible on huggingface. For visualization, please refer to our github repository. (Bellow are some examples of the generated 3D portraits.)

@article{Portrait3D_sig24,
author = {Wu, Yiqian and Xu, Hao and Tang, Xiangjun and Chen, Xien and Tang, Siyu and Zhang, Zhebin and Li, Chen and Jin, Xiaogang},
title = {Portrait3D: Text-Guided High-Quality 3D Portrait Generation Using Pyramid Representation and GANs Prior},
year = {2024},
publisher = {Association for Computing Machinery},
volume = {43},
number = {4},
url = {https://doi.org/10.1145/3658162},
doi = {10.1145/3658162},
journal = {ACM Trans. Graph.},
month = {Jul},
articleno = {45}
}