2026

GenLCA: 3D Diffusion for Full-Body Avatars from In-the-Wild Videos
Yiqian Wu; Rawal Khirodkar; Egor Zakharov; Timur Bagautdinov; Lei Xiao; Zhaoen Su; Shunsuke Saito; Xiaogang Jin; Junxuan Li.
European Conference on Computer Vision (ECCV) 2026 Work was done during an internship at Meta
A diffusion-based generative model for generating and editing photorealistic full-body avatars from text and image inputs.

PixTex: Consistent 3D Texturing via Pixel-Space Multi-View Diffusion
Yuqing Zhang; Yan-Pei Cao; Hao Xu; Yiqian Wu; Sirui Lin; Yuqing Wang; Ding Liang; Yuan-Chen Guo†; Xiaogang Jin†.
ACM SIGGRAPH (Conference Track) 2026
The first pixel-space multi-view diffusion framework for texture generation.
2025

Text-based Animatable 3D Avatars with Morphable Model Alignment
Yiqian Wu; Malte Prinzler; Xiaogang Jin†; Siyu Tang.
ACM SIGGRAPH (Conference Track) 2025 Work was done during visiting ETH Zurich
A novel framework, AnimPortrait3D, for text-based realistic animatable 3DGS avatar generation with morphable model alignment.

3DPortraitGAN: Learning Canonical Full-Head 3D GANs from a Single-View Portrait Dataset with Diverse Body Poses
Yiqian Wu; Hao Xu; Xiangjun Tang; Yue Shangguan; Hongbo Fu; Xiaogang Jin†.
IEEE Transactions on Circuits and Systems for Video Technology 2025
The first 3D-aware one-quarter headshot portrait generator that learns a canonical 3D avatar distribution from the 360°PHQ dataset with body pose self-learning.
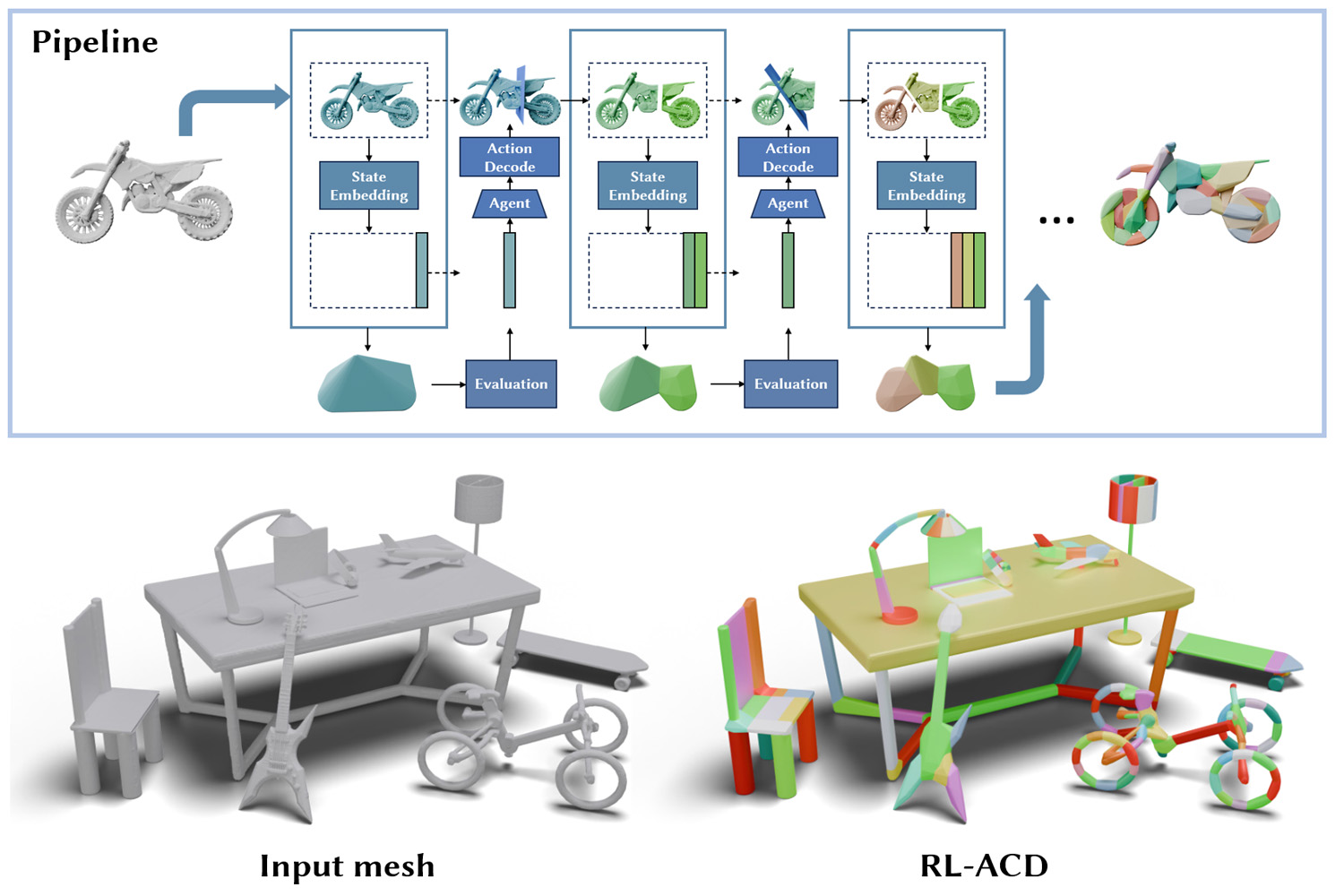
RL-ACD: Reinforcement Learning-based Approximate Convex Decomposition
Yuzhe Luo; Zherong Pan; Kui Wu; Xingyi Du; Yun Zeng; Xiangjun Tang; Yiqian Wu; Xiaogang Jin†; Xifeng Gao†.
ACM Transactions on Graphics (Proceedings of SIGGRAPH Asia) 2025
A data-driven, reinforcement learning-based approach for efficient and near-optimal convex shape decomposition.

LegoACE: Autoregressive Construction Engine for Expressive LEGO Assemblies
Hao Xu; Yuqing Zhang; Yiqian Wu; Xinyang Zheng; Yutao Liu; Xiangjun Tang; Yunhan Yang; Ding Liang; Yingtian Liu; Yuanchen Guo; Yanpei Cao†; Xiaogang Jin†.
ACM SIGGRAPH Asia (Conference Track) 2025
An autoregressive pipeline for LEGO model generation.
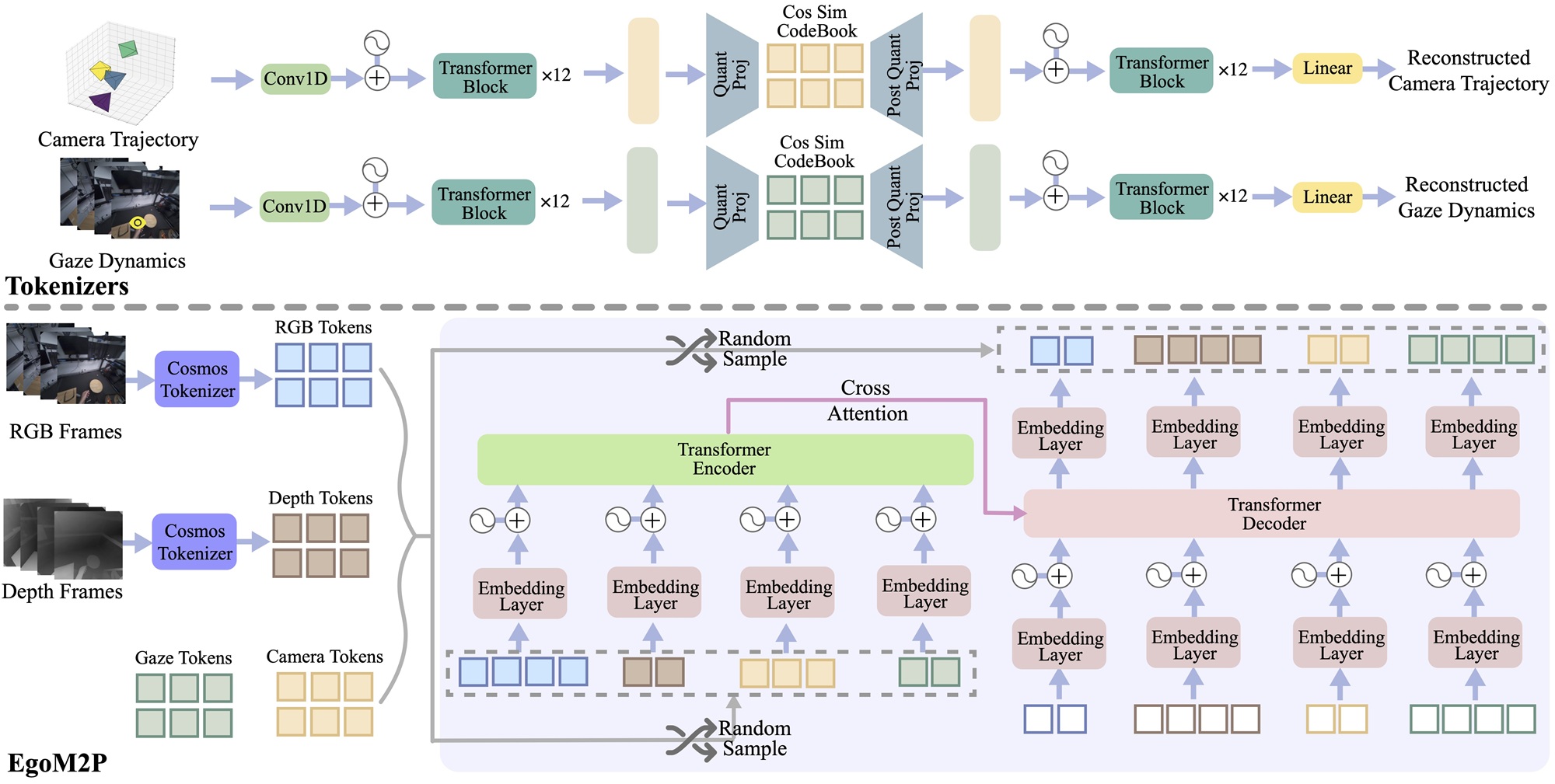
EgoM2P: Egocentric Multimodal Multitask Pretraining
Gen Li; Yutong Chen*; Yiqian Wu*; Kaifeng Zhao*; Marc Pollefeys; Siyu Tang. (* equal contribution )
IEEE/CVF International Conference on Computer Vision (ICCV) 2025
A masked modeling framework that learns from temporally-aware multimodal tokens to train a large, general-purpose model for egocentric 4D understanding.

Semantically Consistent Text-to-Motion with Unsupervised Styles
Linjun Wu; Xiangjun Tang; Jingyuan Cong; He Wang; Bo Hu; Xu Gong; Songnan Li; Yuchen Liao; Yiqian Wu; Chen Liu; Xiaogang Jin†.
ACM SIGGRAPH (Conference Track) 2025
A novel method that integrates unsupervised style from arbitrary references into a text-driven diffusion model to generate semantically consistent stylized human motion.

AlignTex: Pixel-Precise Texture Generation from Multi-view Artwork
Yuqing Zhang; Hao Xu; Yiqian Wu; Sirui Chen; Sirui Lin; Xiang Li; Xifeng Gao; Xiaogang Jin†.
ACM Transactions on Graphics (Proceedings of SIGGRAPH) 2025
A novel framework for pixel-precise texture generation from multi-view artwork.
2024

Portrait3D: Text-Guided High-Quality 3D Portrait Generation Using Pyramid Representation and GANs Prior
Yiqian Wu; Hao Xu; Xiangjun Tang; Xien Chen; Siyu Tang; Zhebin Zhang; Chen Li; Xiaogang Jin†.
ACM Transactions on Graphics (Proceedings of SIGGRAPH) 2024
A novel neural rendering-based framework with a novel joint geometry-appearance prior to achieve text-to-3D-portrait generation.
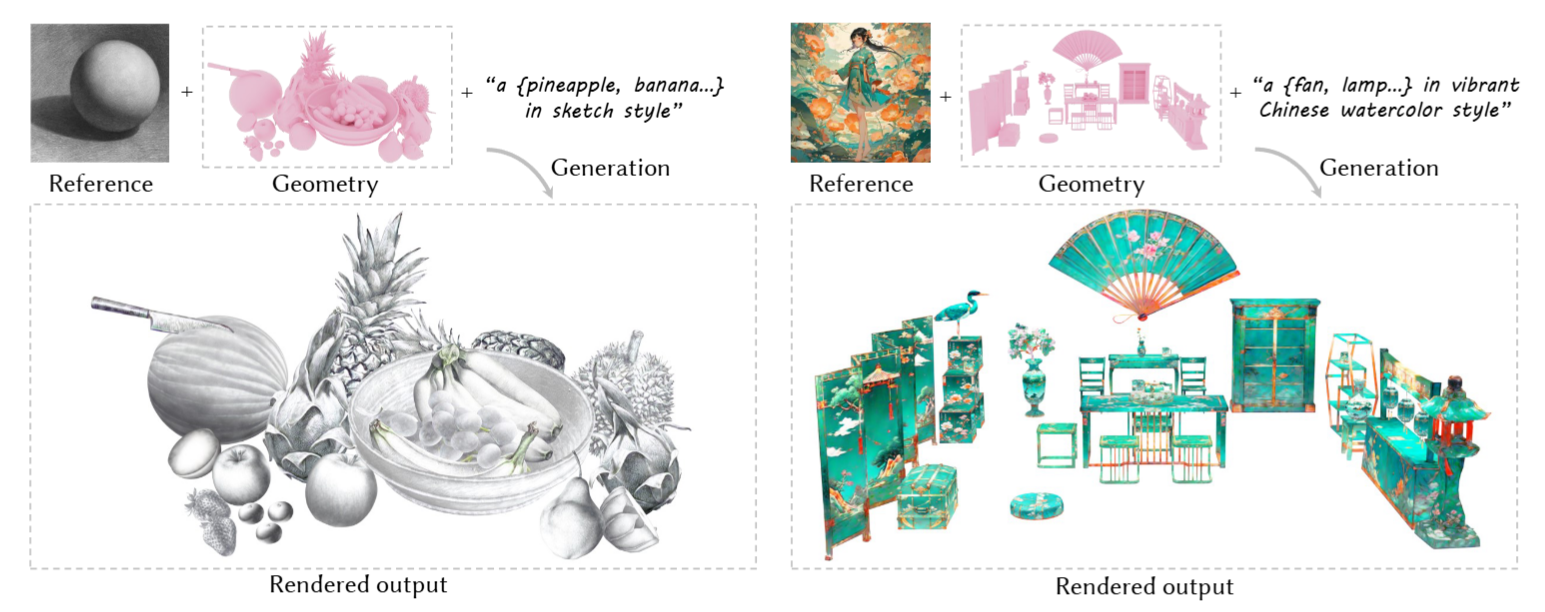
StyleTex: Style Image-Guided Texture Generation for 3D Models
Zhiyu Xie*; Yuqing Zhang*; Xiangjun Tang; Yiqian Wu; Dehan Chen; Gongsheng Li; Xiaogang Jin†. (* equal contribution )
ACM Transactions on Graphics (Proceedings of SIGGRAPH Asia) 2024
An innovative diffusion-model-based framework for creating stylized textures for 3D models.
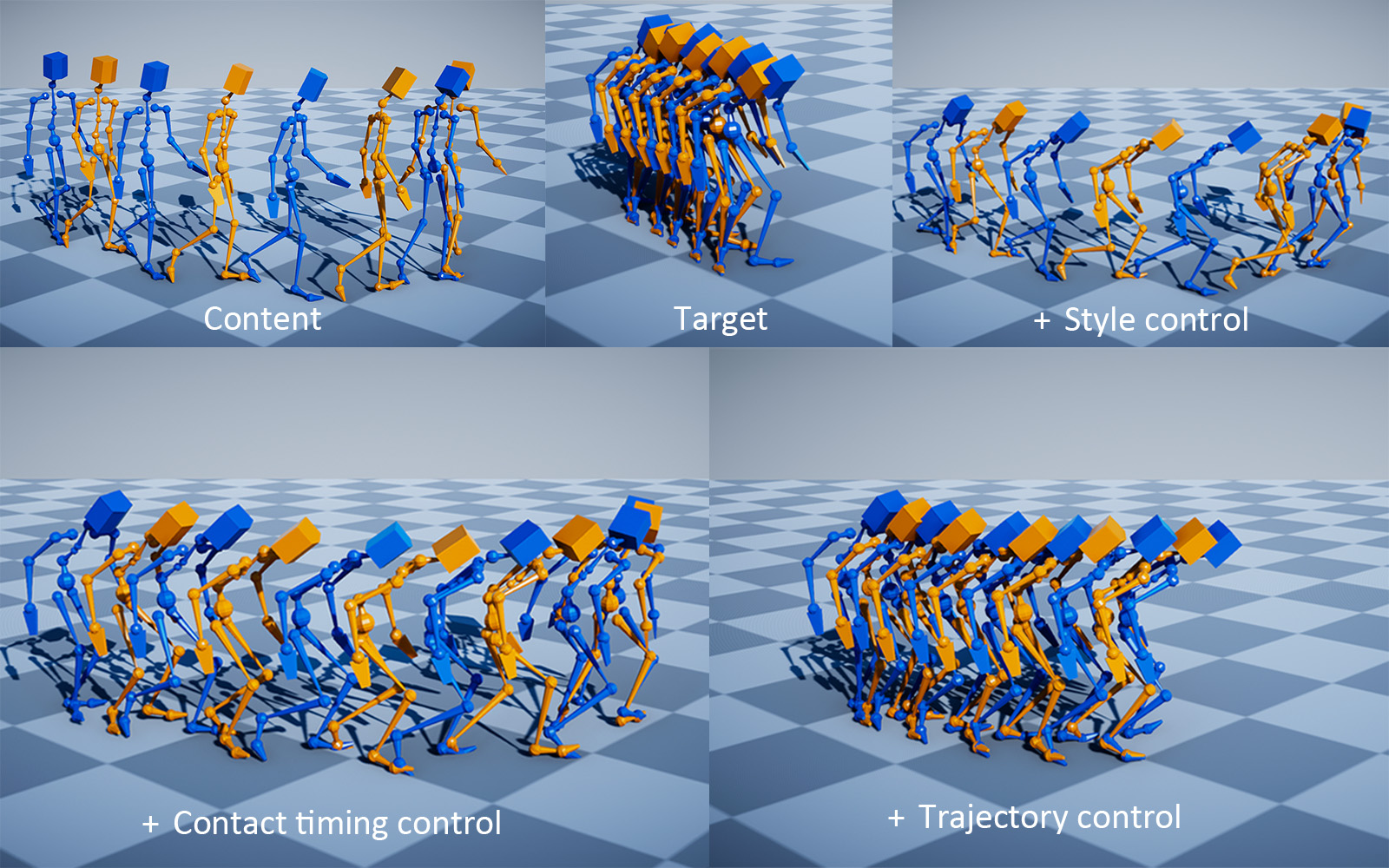
Decoupling Contact for Fine-Grained Motion Style Transfer
Xiangjun Tang; Linjun Wu; He Wang; Yiqian Wu; Bo Hu; Songnan Li; Xu Gong; Yuchen Liao; Qilong Kou; Xiaogang Jin†.
ACM SIGGRAPH Asia (Conference Track) 2024
A novel style transfer method for fine-grained control over contacts while achieving both motion naturalness and spatial temporal variations of style.
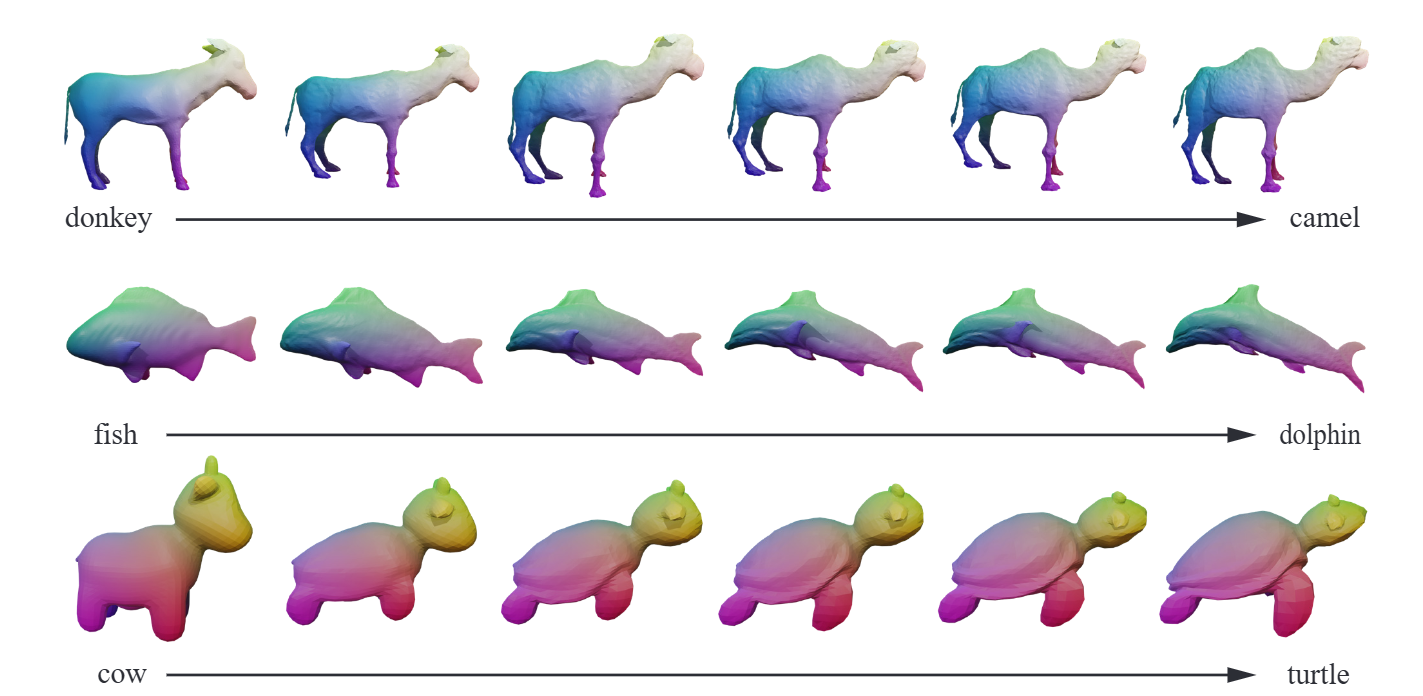
FusionDeformer: Text-guided Mesh Deformation using Diffusion Models
Hao Xu; Yiqian Wu; Xiangjun Tang; Jing Zhang; Yang Zhang; Zhebin Zhang; Chen Li; Xiaogang Jin†.
The Visual Computer 2024
A novel automatic text-guided mesh deformation method that leverages diffusion models.

Enhancing the Authenticity of Rendered Portraits with Identity-Consistent Transfer Learning
Luyuan Wang; Yiqian Wu; Yongliang Yang; Chen Liu; Xiaogang Jin†.
Computer Animation and Virtual Worlds 2024
A novel photo-realistic portrait generation framework that can effectively mitigate the "uncanny valley" effect and improve the overall authenticity of rendered portraits.
2023

LPFF: A Portrait Dataset for Face Generators Across Large Poses
Yiqian Wu; Jing Zhang; Hongbo Fu; Xiaogang Jin†.
IEEE/CVF International Conference on Computer Vision (ICCV) 2023
A large-pose Flickr face dataset comprised of 19,590 high-quality real large-pose portrait images.

Deep Real-time Volumetric Rendering Using Multi-feature Fusion
Jinkai Hu; Chengzhong Yu; Hongli Liu; Lingqi Yan; Yiqian Wu; Xiaogang Jin†.
ACM SIGGRAPH (Conference Track) 2023
A practical framework with a lightweight feature fusion neural network for rendering high-order scattered radiance of participating media in real time.
2022

HairMapper: Removing Hair from Portraits Using GANs
Yiqian Wu; Yongliang Yang; Xiaogang Jin†.
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2022
A dataset and a baseline method for removing hair from portrait images using generative adversarial networks (GANs).
2021

Coarse-to-Fine: Facial Structure Editing of Portrait Images via Latent Space Classifications
Yiqian Wu; Yongliang Yang; Qinjie Xiao; Xiaogang Jin†.
ACM Transactions on Graphics (Proceedings of SIGGRAPH) 2021
A novel method that can automatically remove the double chin effect in portrait images.
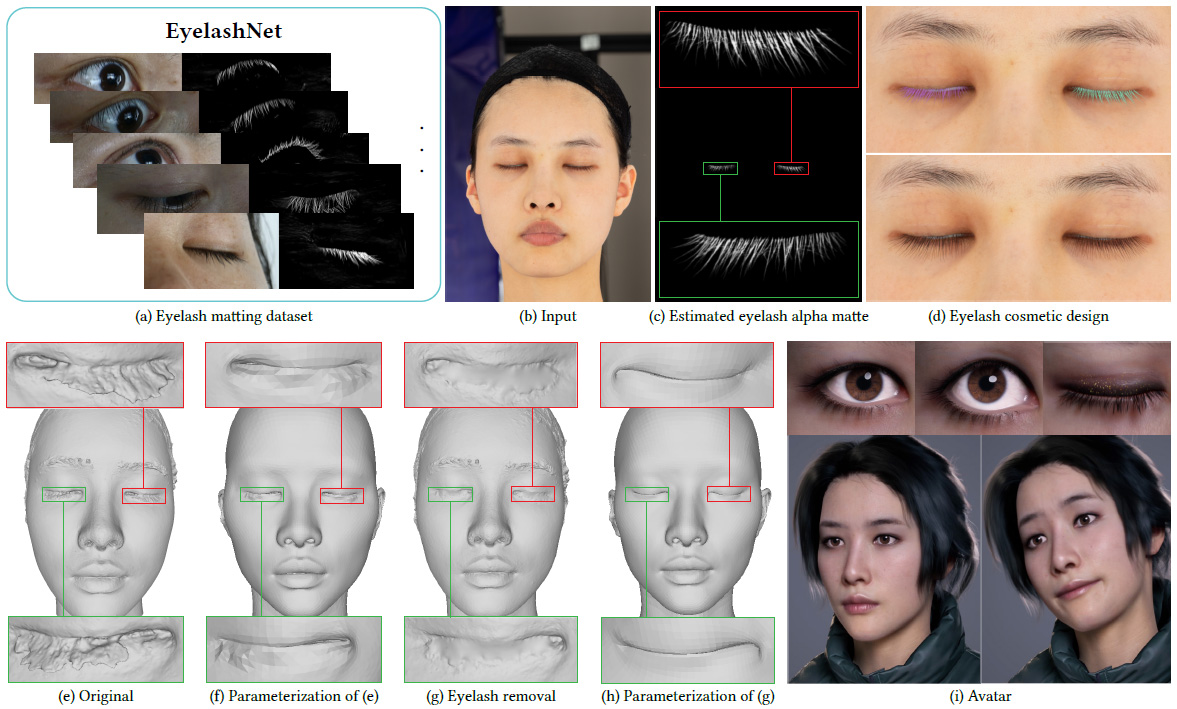
EyelashNet: A Dataset and A Baseline Method for Eyelash Matting
Qinjie Xiao; Hanyuan Zhang; Zhaorui Zhang; Yiqian Wu; Luyuan Wang; Xiaogang Jin†; Xinwei Jiang; Yongliang Yang; Tianjia Shao; Kun Zhou.
ACM Transactions on Graphics (Proceedings of SIGGRAPH Asia) 2021
The first eyelash matting dataset which contains 5,400 high-quality eyelash matting data captured from real world and 5,272 virtual eyelash matting data created by rendering avatars.
2020

iOrthoPredictor: Model-guided Deep Prediction of Teeth Alignment
Lingchen Yang; Zefeng Shi; Yiqian Wu; Xiang Li; Kun Zhou; Hongbo Fu; Youyi Zheng†.
ACM Transactions on Graphics (Proceedings of SIGGRAPH Asia) 2020
A novel system to visually predict teeth alignment in photographs.